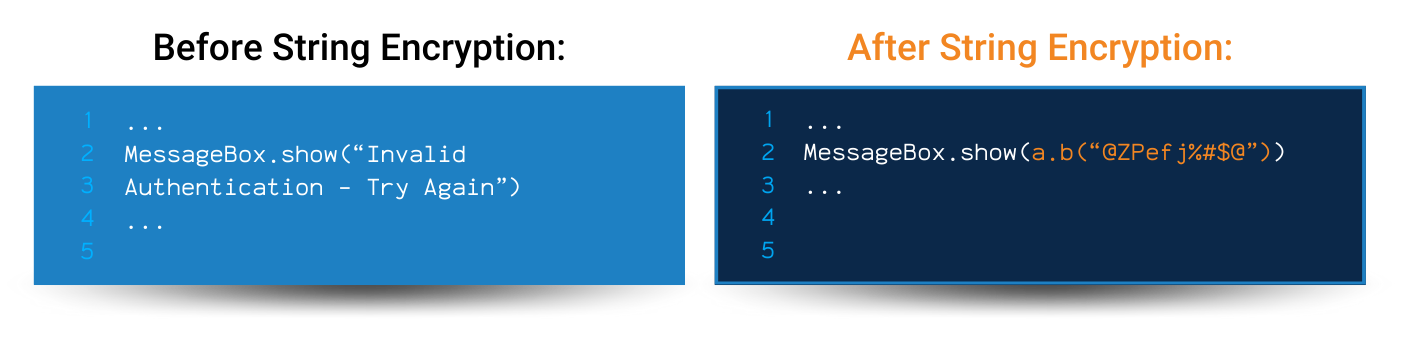
Code Obfuscation is the process of modifying an executable so that it is no longer useful to a hacker but remains fully functional. While the process may modify actual method instructions or metadata, it does not alter the output of the program.
To be clear, with enough time and effort, almost all code can be reverse engineered. However, on some platforms such as Java, Android, iOS, or .NET (e.g. MAUI, C#, VB.NET, F#) free decompilers can easily reverse-engineer source code from an executable or library in virtually no time and with no effort. Automated code obfuscation makes reverse-engineering a program difficult and economically unfeasible.